What Should We Expect from Cloud Providers During an Outage?
June 25th, 2014, by Seth Miller
Reality check: Outages happen. They happen with on premises systems, and they happen in the cloud. It doesn’t matter whose service it is. We could argue about who’s more reliable, but in the end, assuming that you’re up enough of the time that it’s a tenable solution, we generally judge our providers on how they handle the outages.
Here’s How Not to Handle an Outage
There was a fairly widespread and serious Microsoft Lync Online outage on June 23 2014 that lasted for over eight (8) hours, from the late morning into the evening (Eastern Time). During the outage, Lync was completely unavailable to a large group of customers. After the dust settled, we took a look at the way it got handled. A number of things rubbed us the wrong way about this particular case.
It took too long to get diagnosed, acknowledged, and resolved.
At Miller Systems, we primarily use Lync for IM and screen sharing, and the occasional video call. We have alternative methods for doing those things, so this wasn’t the end of the world. But if Lync Online were our primary phone system, as it is for plenty of people, we’d have a pretty severe reaction to a situation like this. If there were a natural disaster, emergency incident, etc., we’d probably cut Microsoft a little slack – but this was plain old-fashioned garden variety “something broke” downtime.
If you expect to use a self-service dashboard for primary support, you’d better come clean – and do it quickly.
We were affected; it was hard to miss. We were all suddenly, forcibly logged out of Lync at around 12:00pm (ET). Microsoft didn’t post their “Investigating” status update (marked as “12:06 pm”) until they also posted an acknowledgment of “Service Degradation” at 12:41 pm.
That’s nearly an hour of “what’s going on?” accompanied by some questionable timeline slight-of-hand. The fact that we didn’t hear a peep from Microsoft until nearly an hour into a “total downtime” for this service is squarely in the “unacceptable” category.
Own the real problem. Don’t spin it – that just upsets customers and makes IT look bad.
Microsoft’s message on the Service Health Dashboard was curiously framed as a relatively mundane sign-in issue…
“Customer Impact: Affected customers are seeing a spinning circle when attempting to sign in to the Lync Online Service. Customers who were connected to the service were signed out, and were then unable to sign back in.”
“Percent of Users Affected: Customers experiencing this issue may see up to 100% of their users affected.”
And then later… once some of the sign in issues were purportedly resolved…
“Upon a successful login, customers may experience reduced functionality.”
Come on, now. If you can’t sign in, you can’t use Lync. Hiding behind “Sign-In” as the only problem is a major cop-out. Fact: this was a total outage. If you’re going to use a dashboard to support users, you have to be truthful.
At this point, given the “reduced functionality” they’ve described to us, how are no other services listed as being in some sort of non-optimal state?
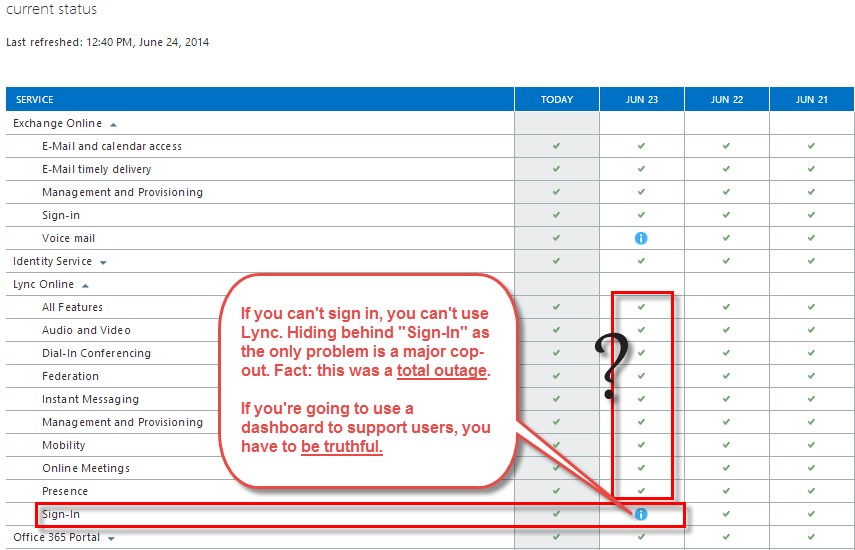
Microsoft’s Service Health Dashboard, after the issue was Resolved. “Sign-In” affects every other feature. Why are all the other features reported as “good”?
Set manageable expectations.
“Restoring Service” started being the message at 1:45 pm. But the issue wasn’t resolved until well into the evening. According to the dashboard, the final resolution was at 8:24 pm ET, but it may have been even longer. That’s too long to expect customers to wait, especially during the business day – but worse, if we see “restoring service” at 1:45, we certainly don’t expect a resolution to take 6-7 hours.
Follow through and provide closure, everywhere you’ve opened a dialog.
Microsoft was kind enough to tweet something at around 4pm ET (and hey, what took so long?), but they never tweeted again to let people know that the issue was resolved. Also, is it that hard to provide a shortlink to the Portal? What if “SHD” (Service Health Dashboard). isn’t part of your everyday vernacular?
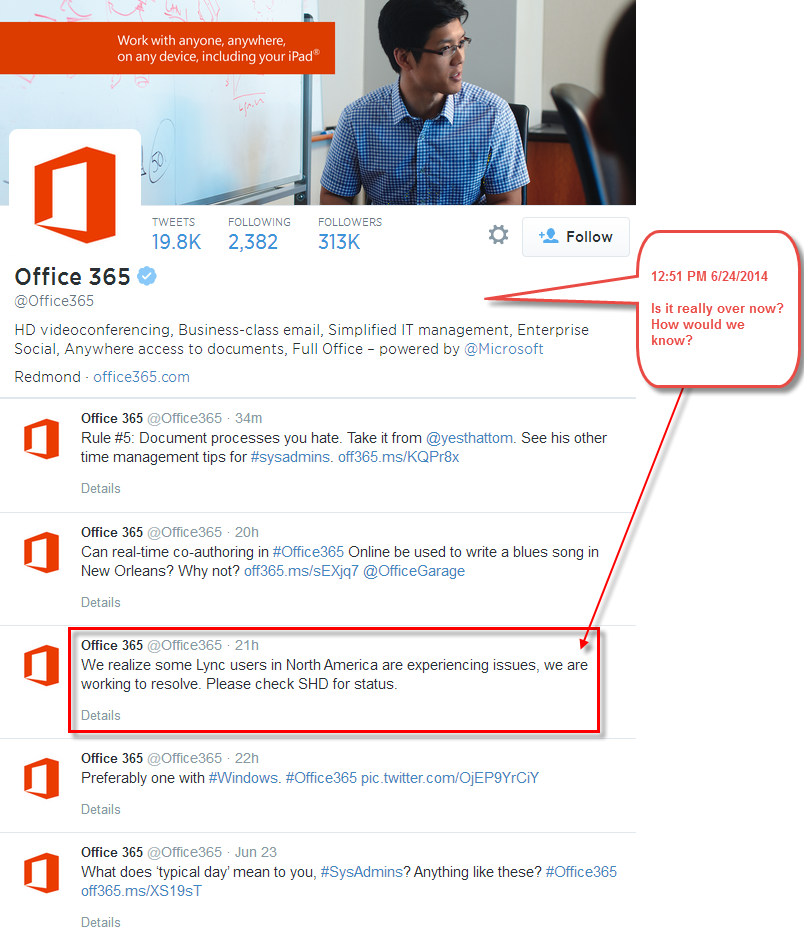
The @Office365 team tweets out that there’s a problem, nearly 4 hours after it starts. Nearly 24 hours later, there’s nothing indicating that the problem was resolved? Not exactly confidence-inspiring.
We did eventually get our hands on a post-incident report, however, we located it on our own. As system admins we would have appreciated any proactive communication directing us to the report – or any other type of incident summary – so we could be confident in the final resolution.
We’re not Microsoft-bashing, but there were clearly a number of opportunities for them to do a better job here. That certainly goes for the tech side of things, but perhaps more importantly, the communication could have been far better than this. Be sure to ask your provider what their process(es) are for handling and communicating similar situations when they arise.
Update 6/25/2014: 2 days later, the Office 365 Twitter account’s last mention of Lync is the one we’ve pointed about in which they acknowledge the outage.
Thanks for the note, Andrew. From your message I am guessing that your group felt the pain a little harder we did. Were you affected on the Exchange side, too? I wondered after reading this article:
http://m.itnews.com/cloud-computing/80950/want-credit-junes-exchange-blackout-file-claim?page=0,1&source=ITNEWSNLE_nlt_itndaily_2014-07-08
As to whether or not the cloud overall is ready for prime time, I think that’s really a case by case call in 2014. It seems to matter an awful lot who’s cloud it is, and what you’re running. One thing that seems pretty clear, regardless of what you’re running (ERP, CRM, email, unified communications, et al): companies with solutions that were built in the cloud from the get-go seem to be in better shape than the established on-premises vendors. Many of them, including Microsoft, seem to still be figuring out how to adapt their solutions into elastic, multi-tenant type environments.
The intent of the article wasn’t to pound Microsoft per se; outages are always tough, and everyone goes down at some point. Hardly unique to our friends in Redmond. But this situation happened to really illustrate just how much the *handling* part matters. There’s no doubt that Microsoft can do better than they did last month. I hope that they will learn from this experience and make improvements – not just in terms of uptime, but to the customer service and communication aspects as well.
Your insight is always appreciated!
Nice article Seth. We also felt the pain of this outage, Microsoft’s communication was certainly lacking… I think this just further proves that “the cloud” isn’t really ready for prime time and it just seems that they are using existing users as their (paying) test subjects!!